Introduction
Deep learning which is a concept based on an artificial neural network (ANN) is a set of machine learning algorithm to obtain the desired information from a large amount of data through a combination of various techniques (Schmidhuber., 2015). ANN reached its peak with the introduction of back-propagation method which is one of optimization method, but it hits a technical limit. So, Kernel method (Support Vector Machine, Gaussian Process etc.) through a nonlinear function were led to the machine learning. The limitations of ANN are many computational problems, initialization problem and local minima problem. The reasons that could solve the problems are pre training using unsupervised learning, development of computer, parallel processing with GPGPU (General-Purpose computing on Graphical Processing Units) and the emergence of Big Data (Deng and Yu., 2014). The deep learning studies give solutions about many problems which have not been resolved by conventional machine learning methods. There are many deep learning algorithms applied on many areas such as DNN (Deep Neural Network), CNN (Convolutional Neural Network), RNN (Recurrent Neural Network). Especially, CNN algorithm shows good performance in image processing field like image classification and image recognition (Girshick et al., 2014). Accordingly, various models of CNNs have been developed, and many studies using them have been conducted. Models are created according to the characteristics of data and fields, and transfer learning using deep learning by importing a pre-training model constructed in good condition environment is also applied (Pan et al., 2010).
One advantage of deep learning such as CNN is it is able to extract feature and analyze data automatically without the professional knowledge for input data. Feature extraction process is important in order to obtain information in data. This process is to determine the performance of the machine learning. A features were extracted by the human judgment previously, but more objective and better feature can be achieved as this process proceeds by including a deep learning algorithms. An automatically extracted feature gives the information that cannot be viewed in the traditional manner and is to broaden the research scope.
Recently agriculture has been able to obtain a variety of information such as images or the environment for the development of the horticulture crop with ICT-based technology. The technology development has been made for market competitiveness and complement vulnerable to crop growth through the information. A large amount of information to form a big data, and conventional method has shown the limits on analyzing this effectively. Accordingly, there is a need to introduce deep learning techniques in agriculture.
The purpose of this study is to apply deep learning techniques to classify the fruit's image. In case of the agricultural sector image classification, support vector machine (SVM) was used for early diagnosis of sugar beet disease (Rumpf et al., 2010) or decision tree method was used to classify the tomato (Yamamoto et al., 2014). Because these algorithms had shortcomings, deep learning algorithm was applied to classification problems. Deep learning algorithm for classifying fruit images was used to CNN which has shown a good performance in image data. The seven kinds of fruit (such as bell pepper, strawberry, orange, etc.) is classified utilizing 120 million training images of ImageNet 2012 and 1,000 test images obtained through Google Images and direct taken images. CAFFE was used as a framework for utilizing CNN.
Materials and Methods
Algorithm: Convolutional Neural Networks (CNN)
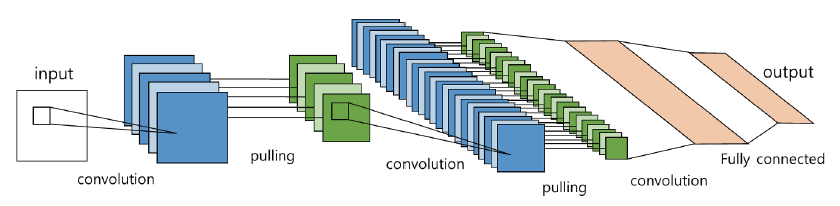
Deep learning algorithm used for image classification was CNN. CNN is composed of a number of convolutional, pooling layer and a general neural network layer which is called as a fully connected layer, shows a good performance for the input data of 2-dimension structure such as image. Convolutional layer makes it possible to extract features without being affected by the size or position of the target on the input image through the convolution operation. Pooling layer reduces the feature through the subsampling in the process to reduce the data increased by the convolutional progress. The convolutional and pooling operation is being repeated, and the feature extraction performance is determined according to this. As the features are obtained through convolutional and pooling layers, the classification task is performed in the final fully connected layer (LeCun et al., 2010). It was used for the GPU possible parallel processing utilizing GPGPU (General-Purpose computing on Graphics Processing Units) concept to train fast, because CNN algorithm requires a lot of computation.
Library (CAFFE) and Programming Language
There are a variety of open source libraries for deep learning such as CAFFE, theano and tensorflow, and this study was to use the CAFFE. CAFFE (Convolutional Architecture for Fast Feature Embedding) which is provided in BVLC (Berkeley Vision and Learning Center) is fast and has the advantage of high degree of freedom. It is written in C++, CUDA (Compute Unified Device Architecture) and makes it possible to change the structure of CNN without any special modification of the code. The components of CAFFE are equal to the following Table 1, LMDB and protobuf especially help to implement deep learning efficiently.

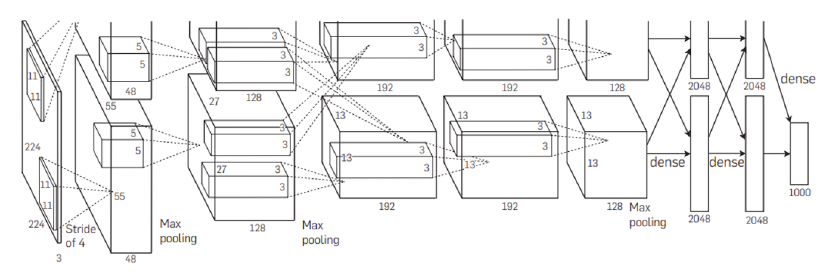
The model used in this study was ‘BVLC Reference CaffeNet’ which is a minor variation version of AlexNet (Krizhevsky et al., 2012) trained on ILSVRC 2012 (ImageNet Large Scale Visual Recognition Challenge 2012) training data. AlexNet consists of eight layers and includes five convolutional layers and three full-connected layers (Fig. 2.). Convolution is performed through filter kernels with sizes of 11, 5 and 3, and ReLU is used as an activation function. It is a large-sized model with 650,000 neurons and consists of a parallel structure based on two GPUs. Python language was used to test the training model and it was carried out through ipython.
The Dataset
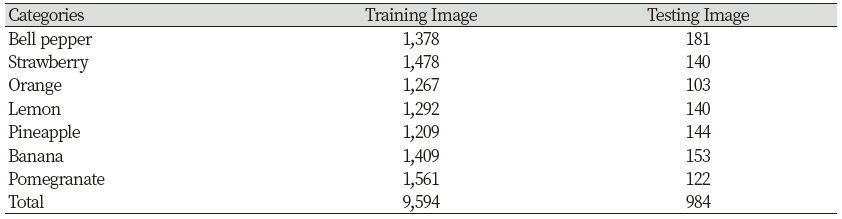
Fig. 3. showed the images used for classification. The training images were a total of 1.2 million labeled images composed of 1,000 categories on ILSVRC 2012 dataset. These images were collected via the web and labeled through a crowdsourcing tool. Validation images were also used by 50,000 images provided by ImageNet. Test images were obtained about 1,000 images through google image search and taken directly from it. For google image, it had got random images of 7 categories of fruit through a program called multi image downloader. The images used for training and testing were not perform any special pre-processing except for the size. It has been acquired under many environmental conditions through various cameras and has a all different background. One image contains more than one object for one kind of fruit, and if not, it is classified into a class that includes many. In addition, the conditions were also diverse, such as cut fruits and fruits containing only the flesh part. The number of each fruit and images used for training and testing was shown in the Table 2.

Process
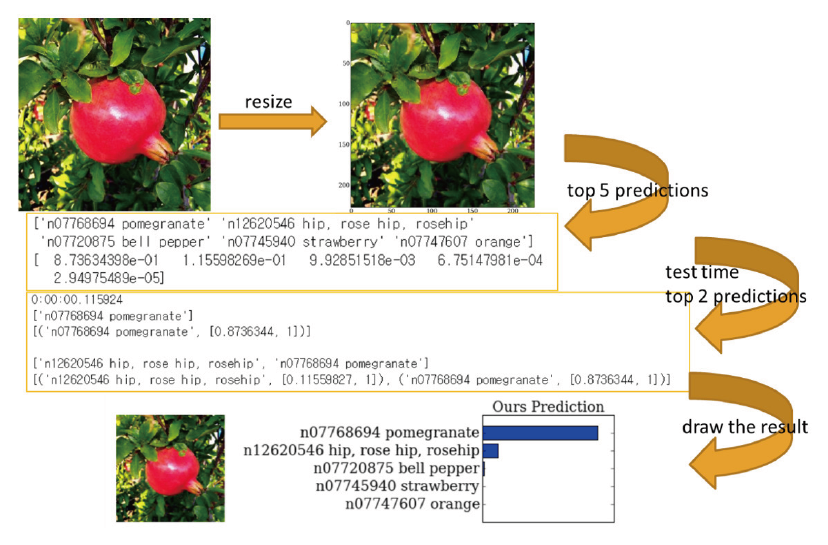
Test images should be down-sampled to a fixed resolution 256×256 to create a constant input dimension, because all the images have different dimensions. A classification was performed with the training model to classify the images to fit the categories after the image labelling, and then spending time, top-1 and top-2 accuracy can be obtained. The results of the compression top-5 with top-2 were saved to text file format, and these were shown through a visualization method. The top-1 means the highest classification category. If the actual label of the image matches the classification label, it gives a score on top-1. Similarly, top-5 is information for the five categories as classified high order. The whole flow is shown Fig. 4.

Results and Discussion
The results for full flow is shown in following Fig. 5. This comes with classification labels and probabilities in text form. The displayed probability values are the values of each category for the input image, so the sum is almost greater than 1.
Before performing image classification using CNN, speed difference between CPU and GPU was checked about the training model. In general, when performing a deep learning algorithm, GPU is used for computational efficiency, so it was necessary to check to what extent the effect actually appeared. Comparing the one-loop rate, which is the ideal time to have one image classification, it is shown that GPU is about 47 times faster with 0.071 seconds for GPU and 3.36 seconds for CPU.
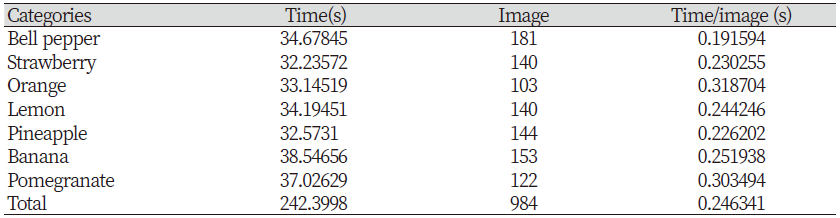
Table 3 shows the speed for all test images. It took about 242 seconds to categorize 984 images, and classification time of one image was about 0.245 seconds. The classification time have nothing to do with the type of fruit. This result is because all images were resized to the same size and the convolution algorithm used to find the features was not significantly affected by the image complexity.
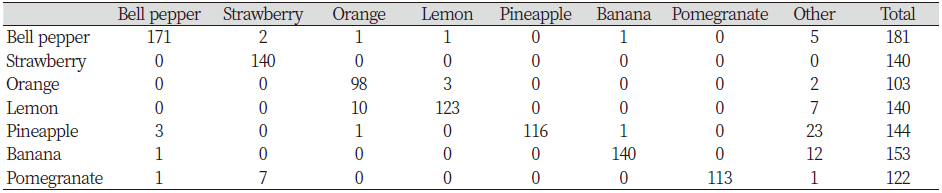
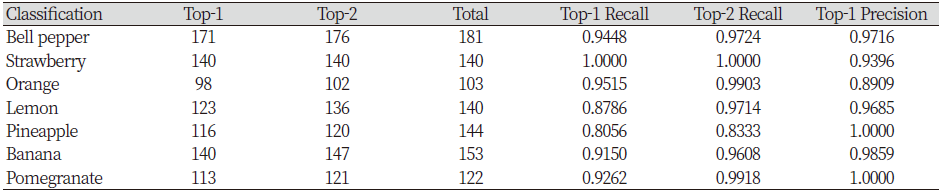
Top-1 classification of each fruit was shown as confusion matrix in Table 4, and Table 5 was classification performance for top-1, top-2. The recall of classification was found to be 0.8056 to 1.00 depending on the fruit. It can be seen to show a very high classification performance as top-1 average recall was 0.9166 and top-2 average recall was 0.9583. This is better than the 88.2% results of the method using the PCA (Principal Component Analysis) and SVM (Zang and Wu., 2012). Moreover, it was confirmed that CNN algorithm was much faster for test time. Top-1 classification results show that the classification recall of lemons and pineapples is relatively lower than that of other categories. Lemon is similar to oranges, so there were many misclassifications about it. Among oranges and lemons, lemons tended to be slightly lower because oranges were classified better. Top-2 classification results for lemon was high because there were fewer misclassifications of different types. In contrast, top-2 classification was also low for pineapple. This is because pineapple images were misclassified into different categories depending on the case where the outer skin (crown, shell) of the fruit was included, and the case where there was only the inner flesh part. As the range of misclassification widened, it is understood that proper classification was not possible with the top-2 result. Unlike recall which was examined in terms of data, precision showed different results. Orange was the lowest value, and the pineapple, which had a low recall value, showed a precision of 1.0. As precision is analyzed in terms of the model, it can be interpreted as a part that shows the classification characteristics of the model different from the data itself. However, the classification as 'other' in addition to the seven fruit categories was not included in the precision, so it can be said that it is insufficient to use in this study. In case of image that is not properly classified, the image included drawing images, cropped images and images which was also difficult to classify by human. If the images were removed from the pre-training process, it will be able to get a better classification results.
Conclusion
In this study, CNN algorithm was used to classify 7 categories fruits. CAFFE which is open source library was used for utilizing CNN algorithm in GPU and programming language was python. It took about 0.25 seconds to classify one image regardless of image complexity, and the type of fruit. The results of 1,000 images classification were shown that top-1 average performance (recall) was 0.9166 and top-2 average recall was 0.9583. This shows that deep learning algorithm can be applied in agriculture area. It is determined that deep learning algorithm is applied to several agricultural parts such as visual part of a crop robot, agricultural recommendation system.

